

我的网站使用 Hugo 编译静态页面。在此基础上,支持了搜索和评论等动态内容。我打算分两篇文章介绍具体的实现方法,分享给读者。
本文先介绍搜索功能的实现方法,还有 另一篇文章 介绍如何添加评论。
效果预览
搜索效果如下:

先决条件
关于搭建静态网站的做法,我在 这篇文章 中有简单介绍。要在静态网站添加动态内容,有如下一些条件:
- 自己掌握的云服务器
- 反向代理(比如nginx)
- 数据库(比如 mysql 或 redis )
具备以上的条件后,我们接下来可以了解下流程。
基本原理
基本的流程是:
- 制定一个用于搜索的路由,不能跟 hugo 项目已有的路由冲突,比如我用的
/s/ - 在 Hugo 项目的页面中创建请求搜索的表单,指向
/s/ - 在 Hugo 项目中,
content目录中建立名叫s的静态内容,作为搜索结果的底版页面。 - 在 Hugo 项目中,在搜索页面中加在 JavaScript 文件,用于向后台请求搜索内容。
- 在 Hugo 项目中,配置 输出文件格式 ,增加一种 txt 格式输出,输出内容为每篇文章的无格式内容。
- 编写后台脚本,用于在 Hugo 项目每次编译后,将输出的 txt 内容写入数据库
- 建立后台搜索服务,从数据库中查找关键字
- 在 nginx 配置中,针对
/s/的请求,分发给后台搜索服务
简单的部署图如下:
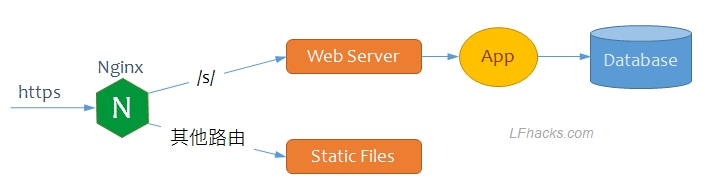
下面分步骤介绍实现方法:
制定路由
路由的名称不能和 Hugo 项目的 content 目录下的内容重复,会被 Hugo 和 nginx 同时使用。我这里使用/s/.
创建表单
页面顶部的表单效果如下:
( ☝ 页面顶栏效果 )
页面顶栏的文件在 Hugo 项目的 layouts/partials/header.html。编辑这个文件,在相关位置添加如下的表单:
<form method='GET' action='/s' class="" id="search-keyword">
<input class="..." id="search-input" maxlength="20" name="s" placeholder="" autocomplete="off" >
<button class="..." type="submit">{{ i18n "search" . }}</button>
</form>
此处省略页面元素的样式属性,因为这取决于各个网站的视觉风格。
这里有两点要注意:
- 表单的请求方法为
GET - 表单的
action属性为事先指定的路由/s/
这个表单填入关键字(比如 李白 )后,会转到 /s/?s=李白 这个链接。后面会处理这个链接。
建立目录
在 Hugo 项目中,content 目录中建立与路由同名(我这里是s)的静态内容,作为搜索结果的底版页面。
比如,我的 content 目录的结构如下:
content
├─ archive
├─ blog
├─ game
├─ grow
├─ nature
├─ ...
└─ s
└─ _index.md
这个 s 页面将被 Hugo 编译并形成一个静态页面,所以需要为这个页面设计一个空的 index 页面 (_index.md),作为搜索结果的页面。搜索结果的内容将在后面章节中使用 Javascript 填充。
index 页面 (_index.md) 的例子:
---
title: 搜索结果
headless: true
---
在 front matter 中设置 headless:true 的原因是:不希望这个页面作为一个普通的页面被统计到归档中去,也不产生其他类型的输出文件。
搜索结果页面样式
在上节中创建的静态页面 /s/,需要一个对应的列表的样式文件,用于指定搜索结果列表的样式。
可以写在 layouts/s/list.html 中。内容举例如下:
{{ define "main" }}
<article class="mx-6 my-8">
<h1 class="text-3xl text-primary-text" id="search-title">{{ .Title }}</h1>
{{ with .Content }}
<div class="content mt-4 text-secondary-text">
{{ . }}
</div>
{{ end }}
</article>
<div class="bg-secondary-bg rounded px-6" id="search-result">
<div class="overflow-hidden divide-y">
</div>
</div>
{{ end }}
注意!上面的样式仅仅是例子,需要读者根据自己的网站的特点设计样式。上面 id 为 #search-result 的 <div>内容是空的,将在下节中使用 JavaScript 填充。
页面发起请求
接下来开始处理 /s/?s=李白 页面向后台发出请求,这个用 Javascript 实现。
由于/s/是静态页面,所以这个 URL 中的 querystring 部分,在正常情况下,不会有没有任何一方来处理。所以可以使用 JavaScript 处理。
如果要让 Hugo 页面加载 js,需要处理两个地方,一个是 layouts/partials/head.html 文件,另一个是新建一个 JavaScript 文件,不妨命名为 search.js ,放在 static 目录下,
在 head.html 文件里加载 js 的部分,增加如下语句:
{{- $assets := .Site.Data.assets }}
{{- if eq .RelPermalink "/s/" }}
<script defer src="{{ $assets.base64.js.url }}"></script>
<script defer src="{{ $assets.search.js.url }}"></script>
{{- end }}
{{ .Site.Data.assets }} 变量指 data/assets.yaml 文件,保存着 search.js 文件的路径。
{{if}} 判断用来确保只有 /s/ 搜索页面才加载这个 js 文件。
search.js 文件的作用主要是将 querystring 编码为 base64,然后向后台发请求。关键的部分如下:
// 处理 querystring
decodeURIComponent(window.location.search.substring(3));
// 填充搜索结果
if(search_title !== null){
if (result.output.length > 0){
search_title.innerHTML = '有关 "'+result.keywords.join(', ') + '" 的 '+result.output.length.toString()+' 条搜索结果'
}else{
search_title.innerHTML = '没有找到 "'+result.keywords.join(', ') + '" 的匹配结果'
}
}
// 向后台发请求
var r = new XMLHttpRequest();
r.addEventListener('load', function () {
var result = JSON.parse(r.responseText)
if(result.status === 'ok'){
populate(result)
}
});
r.open("GET", "/search/"+BASE64.urlsafe_encode(query), true);
r.send(null);
// 加载页面时调用函数
window.onload = getSearchResult
接下来开始处理后台数据,包括内容数据和后台服务。
输出纯文本格式的文章内容
Hugo 编译输出的产物,除了常规的静态 HTML 格式以外,还可以输出多种 MIME type 的文件。具体的格式列表 在这里
为了实现搜索功能,希望只得到每篇文章的文字,而不包括 front matter 和 markdown 的格式信息。先简单了解下 Hugo 输出的逻辑:
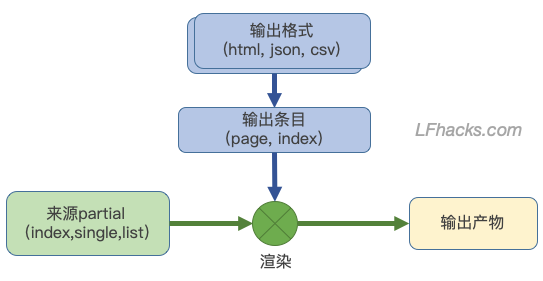
上图中,蓝色方块在 配置文件中枚举出,分别对应 outputFormats 和 outputs,绿色方块在 layouts 目录中出现,黄色的输出则在应该在的地方(取决于来源 partial 的位置,比如首页位置、section位置、每个页面的位置)
下面是具体的实现方法:
首先,修改配置文件(config/_default/config.yaml),增加一种输出格式。在 yaml 格式的最顶层,找到 outputFormats,如果没有就创建一个。像下面这样:
outputFormats:
content:
mediaType: "text/plain"
baseName: "plain-page-content"
isPlainText: true
这样增加了一类名叫 content 的输出格式,参数的含义是:增加的这种输出,采用 “text/plain” 的媒体类型,输出文件的 base name 是 plain-page-content,输出文件的扩展名跟随模板文件的扩展名(这里是 .txt)。在每次编译完成后,我们将在每篇文章的目录中得到 plain-page-content.txt 这个输出文件。
然后,继续修改配置文件,增加一种输出结果,采用上面定义的 content 输出格式。
outputs:
page:
- "html"
- "content"
page 中,原有的 html 是默认的渲染输出,再增加一种 content。
最后,创建输出格式的模板文件,命名规则 在这里:
简单的说,就是 【内容来源】.【输出格式名称】.【输出文件类型】
- 搜索的内容来源来自各个 single页面;
- 输出格式使用上面增加的
content类型; - 输出文件类型可以自由发挥,我们使用最普通的
txt
所以就得到了输出模板的名称:single.content.txt,放置在 layouts/_default/ 目录下。
这个模板的作用,就是将每个页面的 Page 变量,通过模板的格式化,得到渲染的结果。
为了加深理解,看看 layouts/_default/ 目录下的 single.html 文件,它对应的是 config 文件中的 outputs.page.html 输出。
为了得到去掉格式的纯文本,single.content.txt 文件内容如下:
{{ .Plain | htmlUnescape }}
输出纯文本格式的文章标题
用相同的办法,同时输出纯文本格式的标题。具体配置如下:
配置文件(config/_default/config.yaml),增加一种输出格式:
outputFormats:
content:
mediaType: "text/plain"
baseName: "plain-page-content"
isPlainText: true
title:
mediaType: "text/plain"
baseName: "plain-page-title"
isPlainText: true
增加一种输出结果,已有的配置不要删除,只增加就行
outputs:
page:
- "html"
- "content"
- "title"
新建模板:single.title.txt,放置在 layouts/_default/ 目录下,内容为:
{{ print .Title }}
到这里,每次编译结束后,在每篇文章的目录下应该输出两个文件:plain-page-content.txt 和 plain-page-title.txt,内容分别是文章的内容和标题。到这里, Hugo 的改造就结束了,下面要开始编写外部的服务。
设计数据库
要实现高效的搜索,需要使用数据库。这里以 mysql 数据库为例。
安装好 mysql 后,需要首先创建库和表。为了保存搜索结果的来源信息,数据表需要存储文章的所属 section、标题 等信息。
所以表格设计如下:
+----+---------+-------------------------+--------------------------------+--------------+
| id | section | path | title | content |
+----+---------+-------------------------+--------------------------------+--------------+
| 1 | tech | mocha-reporter | 为 Mocha.js 编写自定义的 reporter | 文 |
| 2 | tech | puppeteer-wait-for-ajax | Puppeteer 等待页面更新 | 章 |
| 3 | tech | python-namedtuple | Python 中 NamedTuple 的理解 | 内 |
| .. | ... | ... | ... | 容 |
+----+---------+-------------------------+---------------------------------+--------------+
建表语句为:
CREATE TABLE IF NOT EXISTS `search`(
`id` INT UNSIGNED AUTO_INCREMENT,
`section` VARCHAR(64) NOT NULL,
`path` VARCHAR(255) NOT NULL,
`title` VARCHAR(128) NOT NULL,
`content` TEXT NOT NULL,
PRIMARY KEY ( `id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
section 和 tech 字段用于拼接文章的链接,title 字段用于显示,content 是文章的内容,用于搜索。
编写读取文本文件到数据库的脚本
接下来要编写脚本用来把 Hugo 输出的文本文件(plain-page-content.txt 和 plain-page-title.txt)的内容写入数据库。
对于 mysql 数据库,可以使用 Python 语言的 pymysql 库完成这个任务。有一个陷阱是在读入文件内容后,插入数据库之前,需要处理字符转义:
# 部分语句
from pymysql.converters import escape_string
# 文件内容读入 content
article = escape_string(content)
# 把 article 插入数据库
sql = f'INSERT INTO search(section, path, title, content) values ("{section}", "{path}", "{title}", "{article}")'
建立后台搜索服务
简单的方案使用 Flask 框架建立服务,这个话题可以另开一篇,这里只列出视图函数最关键的部分:
import base64
import urllib
from app.models import Search
from sqlalchemy import and_
import regex as re
# search 是个蓝图,公共前缀是 /search
@search.route('/<string:code>', methods=['GET'])
def search(code):
b_keyword = base64.urlsafe_b64decode(code)
keyword = b_keyword.decode(encoding='utf-8', errors='strict')
unquoted = urllib.parse.unquote(keyword)
keywords = set([x.strip() for x in unquoted.split('+') if x])
if keywords:
criteria = [Search.content.like(f'%{w}%') for w in keywords]
records = Search.query.filter(and_(*criteria)).limit(max_results).all()
另外再配合安装 gunicorn 和 supervisord 就可以开启 web 服务,这里假设web 服务开在 8888 端口。
配置 nginx
需要配置 nginx ,将 /s/ 的请求转发到后台 web 服务上,而其余的请求仍然解释为静态文件:
location ~ /search/ {
proxy_pass http://127.0.0.1:8888;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
这样就实现了 Hugo 静态内容配合使用的动态搜索功能。
各位读后有什么想法,请在下方留言吧!如果对本文有疑问或者寻求合作,欢迎 联系邮箱 。邮箱已到剪贴板
精彩评论
本站 是个人网站,采用 署名协议 CC-BY-NC 授权。
欢迎转载,请保留原文链接 https://www.lfhacks.com/tech/dynamic-content-on-static-site-1/ ,且不得用于商业用途。